Free Open-Source Artificial Intelligence
2764 readers
1 users here now
Welcome to Free Open-Source Artificial Intelligence!
We are a community dedicated to forwarding the availability and access to:
Free Open Source Artificial Intelligence (F.O.S.A.I.)
More AI Communities
LLM Leaderboards
Developer Resources
GitHub Projects
FOSAI Time Capsule
- The Internet is Healing
- General Resources
- FOSAI Welcome Message
- FOSAI Crash Course
- FOSAI Nexus Resource Hub
- FOSAI LLM Guide
founded 1 year ago
MODERATORS
1
Meta has released and open-sourced Llama 3.1 in three different sizes: 8B, 70B, and 405B
This new Llama iteration and update brings state-of-the-art performance to open-source ecosystems.
If you've had a chance to use Llama 3.1 in any of its variants - let us know how you like it and what you're using it for in the comments below!
Llama 3.1 Megathread
For this release, we evaluated performance on over 150 benchmark datasets that span a wide range of languages. In addition, we performed extensive human evaluations that compare Llama 3.1 with competing models in real-world scenarios. Our experimental evaluation suggests that our flagship model is competitive with leading foundation models across a range of tasks, including GPT-4, GPT-4o, and Claude 3.5 Sonnet. Additionally, our smaller models are competitive with closed and open models that have a similar number of parameters.
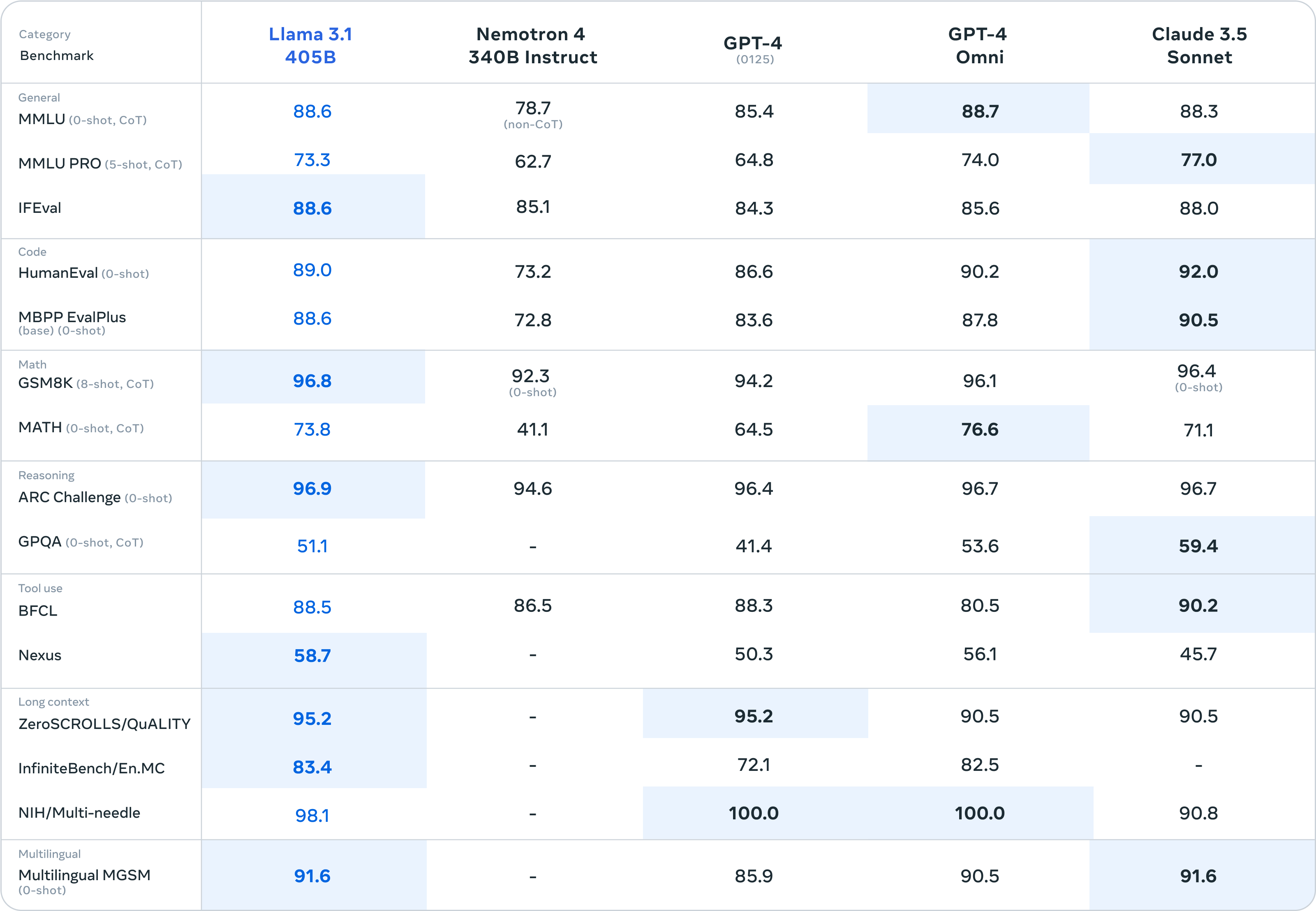
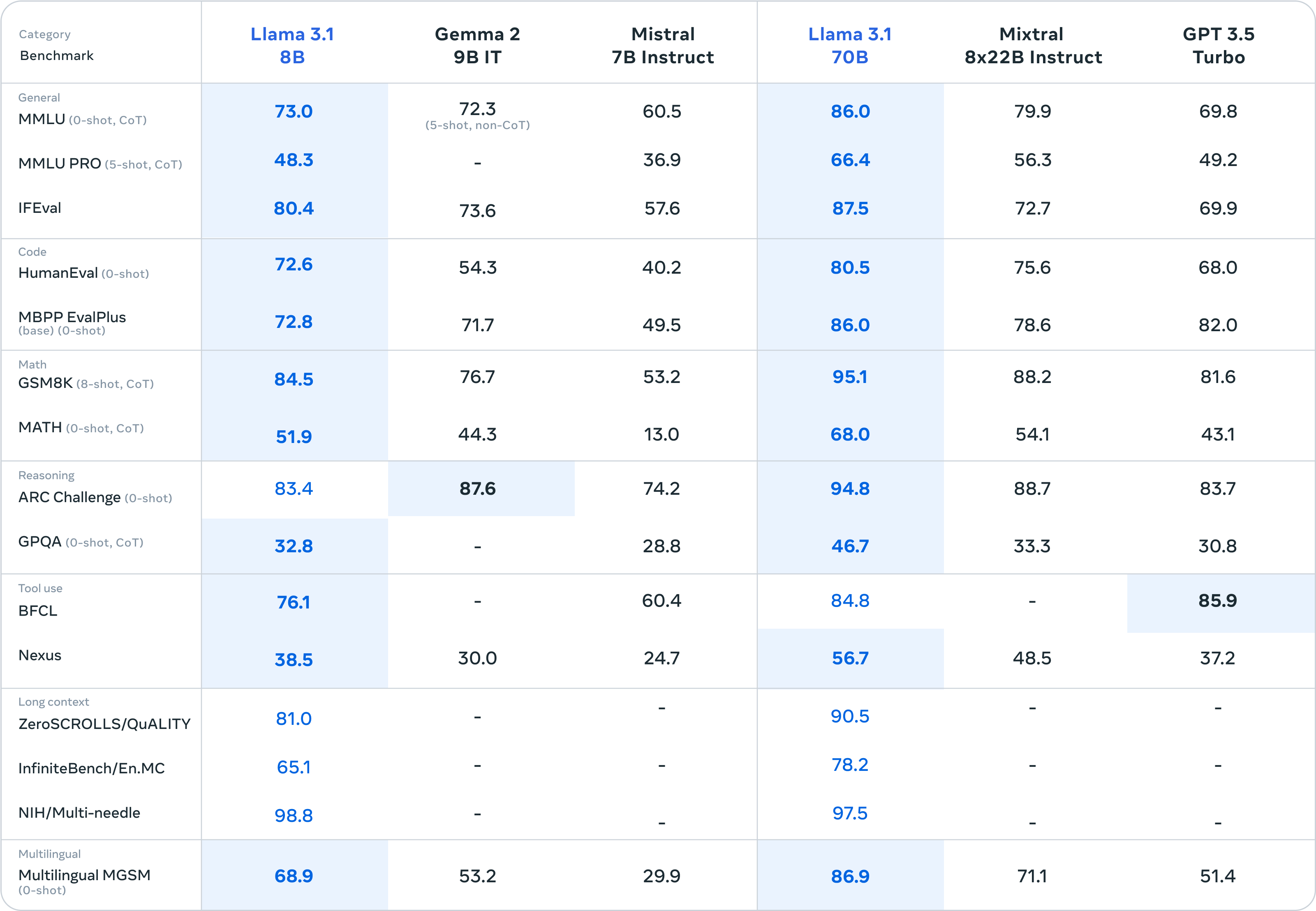
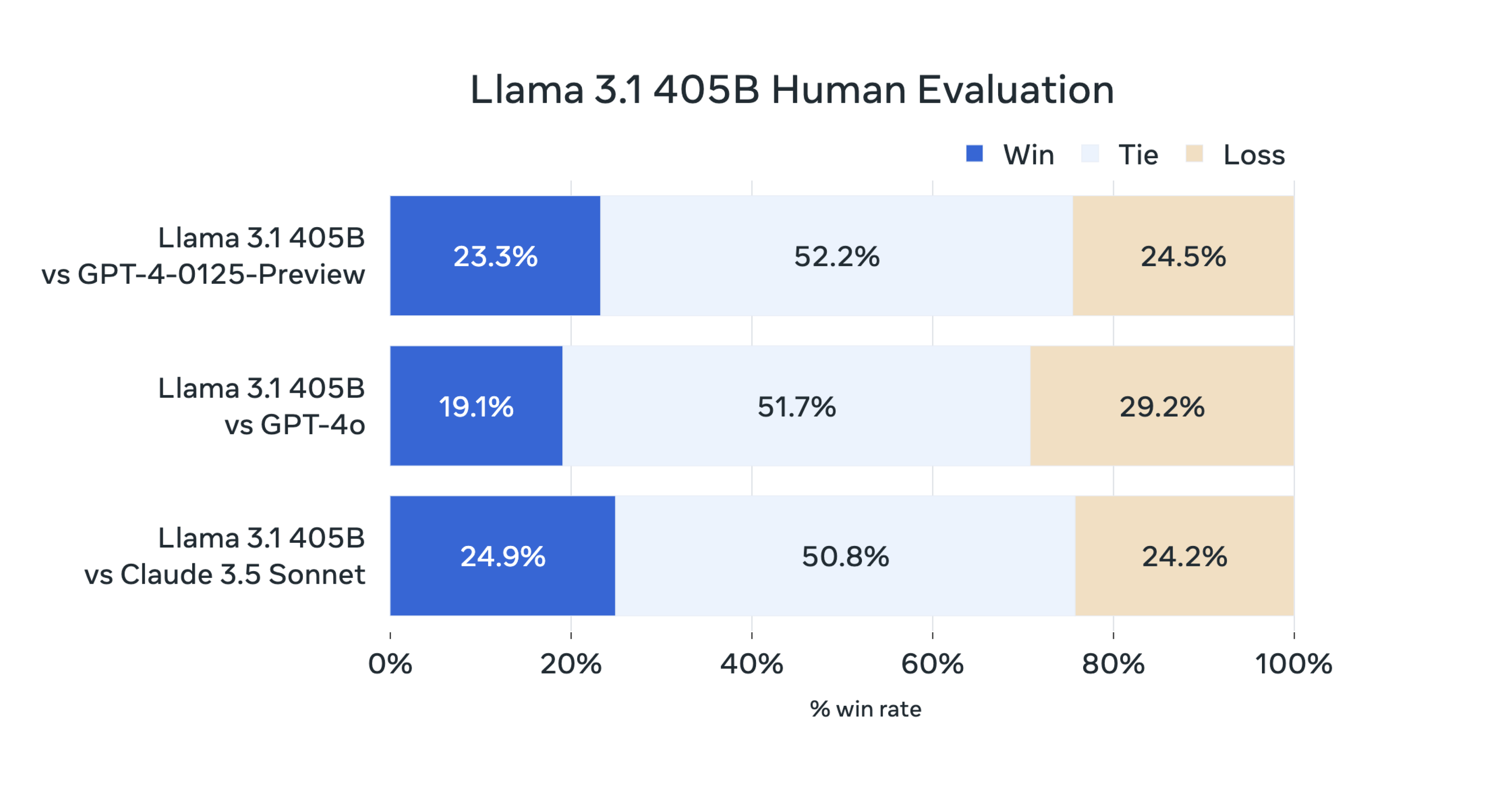
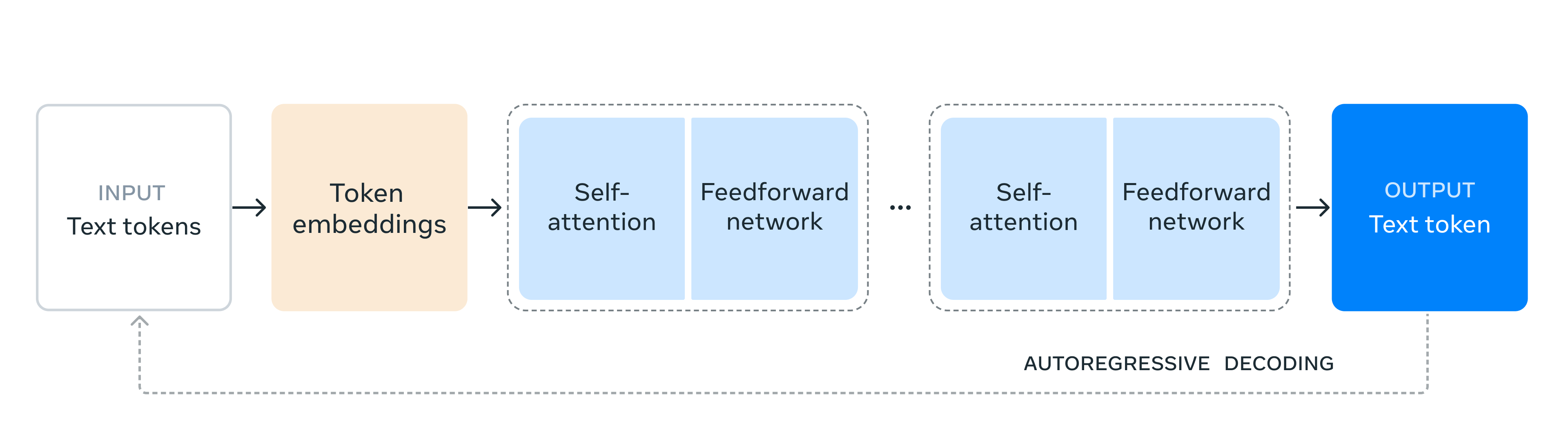
As our largest model yet, training Llama 3.1 405B on over 15 trillion tokens was a major challenge. To enable training runs at this scale and achieve the results we have in a reasonable amount of time, we significantly optimized our full training stack and pushed our model training to over 16 thousand H100 GPUs, making the 405B the first Llama model trained at this scale.
Official Meta News & Documentation
- https://llama.meta.com/
- https://ai.meta.com/blog/meta-llama-3-1/
- https://llama.meta.com/docs/overview
- https://llama.meta.com/llama-downloads/
- https://github.com/meta-llama/llama-models/blob/main/models/llama3_1/MODEL_CARD.md
See also: The Llama 3 Herd of Models paper here:
HuggingFace Download Links
8B
Meta-Llama-3.1-8B
Meta-Llama-3.1-8B-Instruct
Llama-Guard-3-8B
Llama-Guard-3-8B-INT8
70B
Meta-Llama-3.1-70B
Meta-Llama-3.1-70B-Instruct
405B
Meta-Llama-3.1-405B-FP8
Meta-Llama-3.1-405B-Instruct-FP8
Meta-Llama-3.1-405B
Meta-Llama-3.1-405B-Instruct
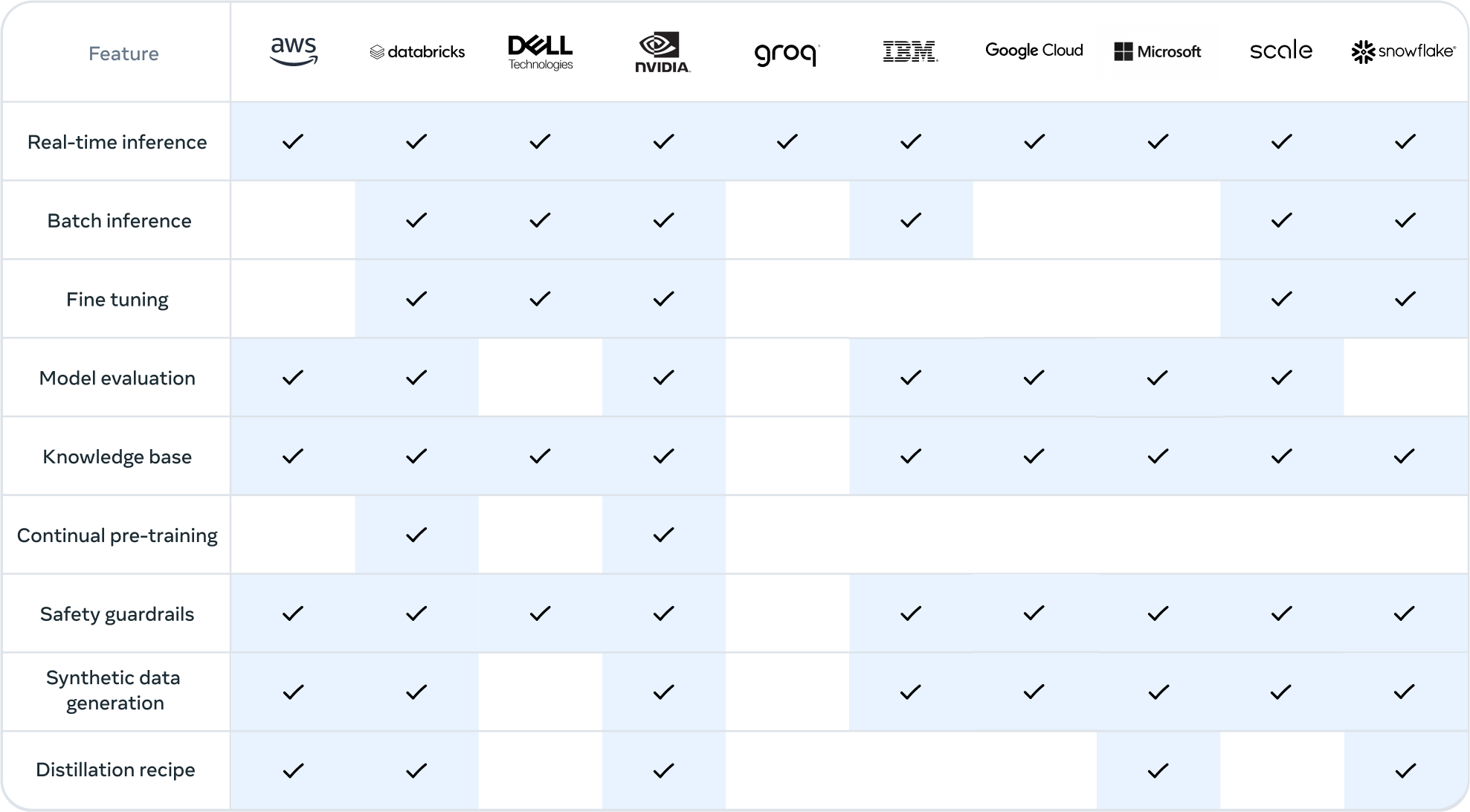
Getting the models
You can download the models directly from Meta or one of our download partners: Hugging Face or Kaggle.
Alternatively, you can work with ecosystem partners to access the models through the services they provide. This approach can be especially useful if you want to work with the Llama 3.1 405B model.
Note: Llama 3.1 405B requires significant storage and computational resources, occupying approximately 750GB of disk storage space and necessitating two nodes on MP16 for inferencing.
Learn more at:
Running the models
Linux
Windows
Mac
Cloud
More guides and resources
How-to Fine-tune Llama 3.1 models
Quantizing Llama 3.1 models
Prompting Llama 3.1 models
Llama 3.1 recipes
YouTube media
Rowan Cheung - Mark Zuckerberg on Llama 3.1, Open Source, AI Agents, Safety, and more
Matthew Berman - BREAKING: LLaMA 405b is here! Open-source is now FRONTIER!
Wes Roth - Zuckerberg goes SCORCHED EARTH.... Llama 3.1 BREAKS the "AGI Industry"*
1littlecoder - How to DOWNLOAD Llama 3.1 LLMs
Bloomberg - Inside Mark Zuckerberg's AI Era | The Circuit
2
3
4
5
cross-posted from: https://lemmy.toldi.eu/post/984660
Another day, another model.
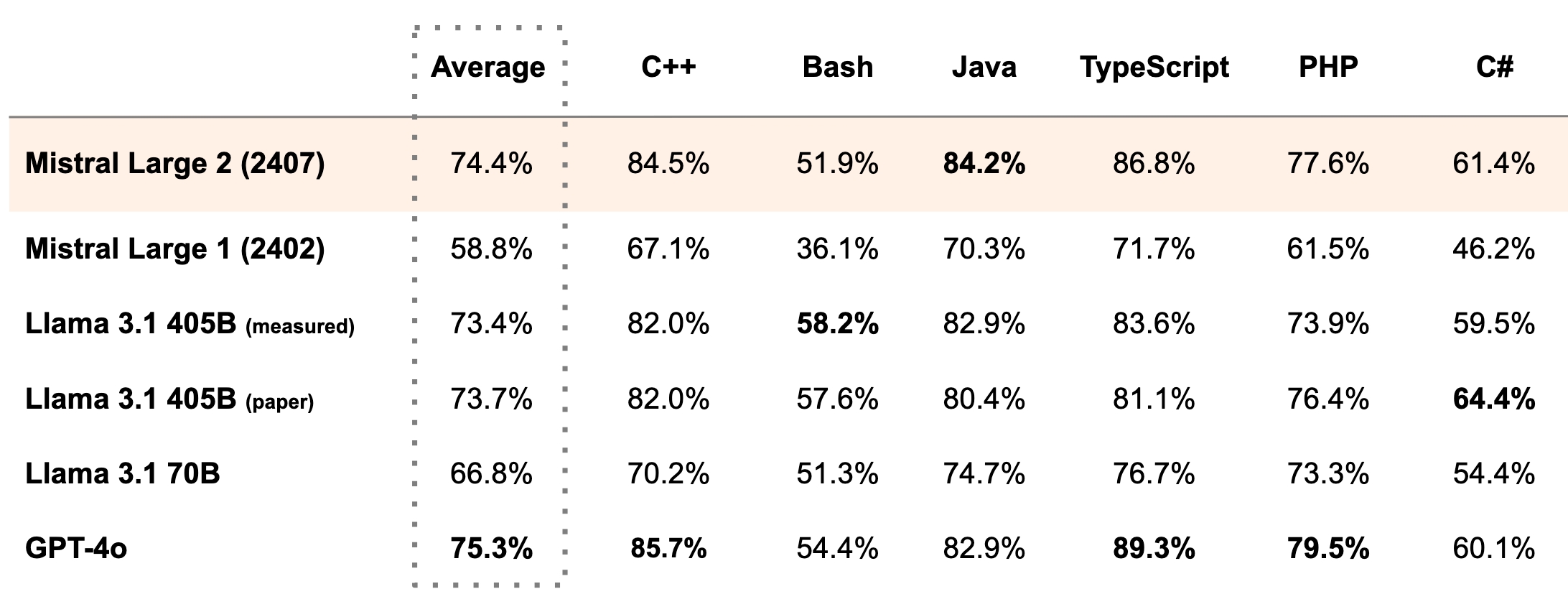
Just one day after Meta released their new frontier models, Mistral AI surprised us with a new model, Mistral Large 2.
It's quite a big one with 123B parameters, so I'm not sure if I would be able to run it at all. However, based on their numbers, it seems to come close to GPT-4o. They claim to be on par with GPT-4o, Claude 3 Opus, and the fresh Llama 3 405B regarding coding related tasks.
It's multilingual, and from what they said in their blog post, it was trained on a large coding data set as well covering 80+ programming languages. They also claim that it is "trained to acknowledge when it cannot find solutions or does not have sufficient information to provide a confident answer"
On the licensing side, it's free for research and non-commercial applications, but you have to pay them for commercial use.
6
7
8
ABSTRACT
The past year has seen a steep rise in generative AI systems that claim to be open. But how open are they really? The question of what counts as open source in generative AI is poised to take on particular importance in light of the upcoming EU AI Act that regulates open source systems differently, creating an urgent need for practical openness assessment. Here we use an evidence-based framework that distinguishes 14 dimensions of openness, from training datasets to scientific and technical documentation and from licensing to access methods. Surveying over 45 generative AI systems (both text and text-to-image), we find that while the term open source is widely used, many models are ‘open weight’ at best and many providers seek to evade scientific, legal and regulatory scrutiny by withholding information on training and fine-tuning data. We argue that openness in generative AI is necessarily composite (consisting of multiple elements) and gradient (coming in degrees), and point out the risk of relying on single features like access or licensing to declare models open or not. Evidence-based openness assessment can help foster a generative AI landscape in which models can be effectively regulated, model providers can be held accountable, scientists can scrutinise generative AI, and end users can make informed decisions.

Figure 2 (click to enlarge): Openness of 40 text generators described as open, with OpenAI’s ChatGPT (bottom) as closed reference point. Every cell records a three-level openness judgement (✓ open, ∼ partial or ✗ closed). The table is sorted by cumulative openness, where ✓ is 1, ∼ is 0.5 and ✗ is 0 points. RL may refer to RLHF or other forms of fine-tuning aimed at fostering instruction-following behaviour. For the latest updates see: https://opening-up-chatgpt.github.io

Figure 3 (click to enlarge): Overview of 6 text-to-image systems described as open, with OpenAI's DALL-E as a reference point. Every cell records a three-level openness judgement (✓ open, ∼ partial or ✗ closed). The table is sorted by cumulative openness, where ✓ is 1, ∼ is 0.5 and ✗ is 0 points.
There is also a related Nature news article: Not all ‘open source’ AI models are actually open: here’s a ranking
PDF Link: https://dl.acm.org/doi/pdf/10.1145/3630106.3659005
9
10
11
12
13
14
15
16
17
18
Abstract
We introduce ToonCrafter, a novel approach that transcends traditional correspondence-based cartoon video interpolation, paving the way for generative interpolation. Traditional methods, that implicitly assume linear motion and the absence of complicated phenomena like dis-occlusion, often struggle with the exaggerated non-linear and large motions with occlusion commonly found in cartoons, resulting in implausible or even failed interpolation results. To overcome these limitations, we explore the potential of adapting live-action video priors to better suit cartoon interpolation within a generative framework. ToonCrafter effectively addresses the challenges faced when applying live-action video motion priors to generative cartoon interpolation. First, we design a toon rectification learning strategy that seamlessly adapts live-action video priors to the cartoon domain, resolving the domain gap and content leakage issues. Next, we introduce a dual-reference-based 3D decoder to compensate for lost details due to the highly compressed latent prior spaces, ensuring the preservation of fine details in interpolation results. Finally, we design a flexible sketch encoder that empowers users with interactive control over the interpolation results. Experimental results demonstrate that our proposed method not only produces visually convincing and more natural dynamics, but also effectively handles dis-occlusion. The comparative evaluation demonstrates the notable superiority of our approach over existing competitors.
Paper: https://arxiv.org/abs/2405.17933v1
Code: https://github.com/ToonCrafter/ToonCrafter
Project Page: https://doubiiu.github.io/projects/ToonCrafter/
Limitations
Input starting frame

Input ending frame

Our failure case
Input starting frame

Input ending frame

Our failure case
19
20
21
23
24
25
view more: next ›