bahmanm
To be fair, here's the complete paragraph which makes sense:
Vagrant public networks are less private than private networks, and the exact meaning actually varies from provider to provider, hence the ambiguous definition. The idea is that while private networks should never allow the general public access to your machine, public networks can.
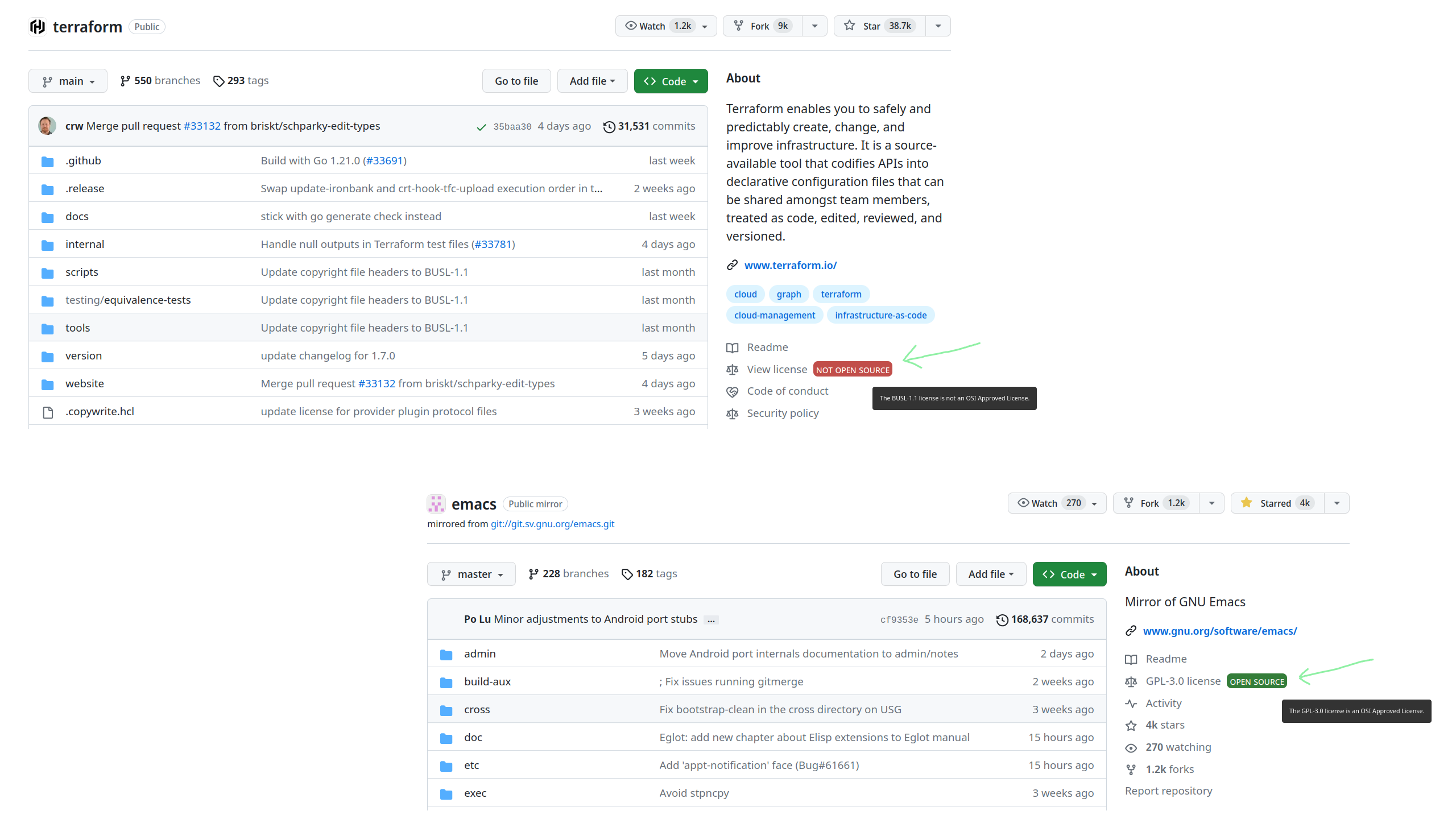
I am not the author.
https://github.com/galdor/github-license-observer
https://addons.mozilla.org/en-GB/android/addon/github-license-observer/
This is a cool little addon to help you tell, at a glance, if the repository you're browsing on github has an open source license license.
Especially relevant nowadays given the trend to convert previously OS repos to non-OS licenses as a business model (eg Akka or Terraform.)